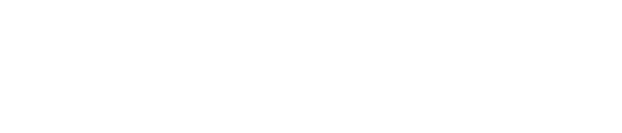Case StudyAIMental HealthBringing Treatment-Resistant Depression to Light: AI-Driven Patient Discovery in Real-World DataRead more
Case StudyAIDermRareUsing Artificial Intelligence to Find Undiagnosed Generalized Pustular Psoriasis PatientsRead more
Case StudyDataNeuroSupporting payer adoption with real-world evidence: Nalu Medical demonstrates value with OM1 dataRead more
BlogRegistriesDataOtherFDA Draft Guidance Signals a New Era for Post-Approval Data in Cell & Gene TherapyRead more
BlogLeveraging Real-World and Passive Data to Significantly Improve Site Satisfaction and Reduce Trial CostsRead more
PublicationClinical Relevance of a Machine Learning Model for Automated Analyses of Depression Severity: the ePHQ-9 in Treatment-Resistant DepressionDownload
PublicationRegistriesOtherRegistry of Patient Registries Outcome Measures Framework: Information Model Report.Read more
PublicationRegistriesOtherDevelopment of Harmonized Outcome Measures for Use in Patient Registries and Clinical Practice: Methods and Lessons Learned. Final ReportRead more
PublicationAIRareA New Approach to Identifying Patients with Elevated Risk for Fabry Disease Using a Machine Learning Algorithm.Read more
PublicationRegistriesDataOncologyComparison of Resource Utilization and Clinical Outcomes Following Screening with Digital Breast Tomosynthesis Versus Digital Mammography: Findings From a Learning Health SystemRead more
PublicationDataRespiratoryReal-World Evidence Analysis of the Impact of Steroid-Eluting Implants on Healthcare Resource Use Among Chronic Rhinosinusitis Patients Undergoing Sinus SurgeryRead more
PublicationDataRespiratoryReduction in healthcare resource use through 24 months following sinus surgery with steroid-eluting implants in chronic rhinosinusitis patients with and without nasal polyps: a real-world studyRead more
PublicationAICardioPredicting Disease Progression in Non-Alcoholic Steatohepatitis (NASH) Patients with Early Stage Fibrosis Within a Large, Representative Real-World Database of US PatientsRead more
PublicationAICardioA Highly Predictive Machine Learning Model to Identify Hospitalized Patients at Risk for 30-day Readmission or MortalityRead more
PublicationDataCardioStandardized Library of Atrial Fibrillation Outcome Measures. Research White Paper.Read more
PublicationDataCardioHarmonized Outcome Measures for Use in Atrial Fibrillation Patient Registries and Clinical PracticeRead more
PublicationAINeuroValidation of a Machine Learning Approach to Estimate Expanded Disability Status Scale Scores for Multiple Sclerosis.Read more
PublicationDataNeuroReal-world healthcare utilization and costs of peripheral nerve stimulation with a micro-IPG systemRead more
PublicationDataMental HealthWeight Gain and Comorbidities Associated With Oral Second-Generation Antipsychotics: Analysis of Real-World Data for Patients With Bipolar I Disorder or SchizophreniaRead more
PublicationAIMental HealthA machine learning model using clinical notes to estimate PHQ-9 symptom severity scores in depressed patientsRead more
PublicationDataMental HealthReal-world effectiveness of cariprazine in major depressive disorder and bipolar I disorder in the United StatesRead more
PublicationDataMental HealthClinical burden of major depressive disorder with versus without prominent anhedonia using a real-world electronic health records and claims linked databaseRead more
PublicationDataOtherImpact of New Guidelines for High Blood Pressure: Findings from the OM1 Intelligent Data CloudDownload
PublicationDataRegistriesOtherAssessing Real-World Data Quality: The Application of Patient Registry Quality Criteria to Real-World Data and Real-World EvidenceDownload
PublicationDataOncologyHarmonized Outcome Measures for Use in Non–Small Cell Lung Cancer Patient Registries and Clinical PracticeDownload
PublicationDataOncologyRepresentation of patients of minority race and ethnicity in real-world databases and tumor registries of patients with breast cancerDownload
PublicationRegistriesOncologyMammography screening outcomes for women screened by standard versus high resolution digital breast tomosynthesisDownload
PublicationAIDermUsing AI to Predict Progression from Psoriasis to Psoriatic Arthritis in a Real-World Dataset.Download
PublicationAICardioMachine Learning Generated Risk Model to Predict Unplanned Hospital Admission in Heart FailureDownload
PublicationDataNeuroUsing Real-World Data and Digital Phenotyping to Identify Candidates for anti-CGRP Migraine TreatmentDownload
PublicationDataNeuroDiagnosis of Frontotemporal Dementia is Often in Non-Specialist Settings and Complicated by Non-FTD Dementia and Psychiatric DiagnosesDownload
PublicationDataMental HealthHarmonized Outcome Measures for Use in Depression Patient Registries and Clinical PracticesDownload
PublicationDataMental HealthReductions in Depressive Symptoms After Brexpiprazole Augmentation Among Patients with Major Depressive Disorder Receiving Antidepressant Therapy in Real-World SettingsDownload
PublicationAIMental HealthDevelopment of a Machine Learning Model for Estimating CGI-I Scores Using Electronic Medical Records from Real-World Data Sources in Schizophrenia, Bipolar I and Major Depressive DisorderDownload
PublicationRegistriesOncologyTowards Personalized Breast Imaging Pathways: Initial Findings from a Learning Health System.Download
PublicationRegistriesDataOncologyDisparities in Accessing Screening Mammography: Opportunities for Improving Diagnostic OutcomesDownload
PublicationRegistriesOncologyUsing Real-World Evidence to Support a Changing Paradigm for Cancer Screening: A CommentaryDownload
PublicationRegistriesOncologyOutcomes by Race in Breast Cancer Screening With Digital Breast Tomosynthesis Versus Digital MammographyRead more
PublicationDataGastroMethod to Derive a Modified Mayo Score from Electronic Health Records DataDownload
PublicationDataDermTreatment Supplementation Following Dupilumab Initiation in Real-World Patients With Atopic Dermatitis in the U.S.Download
PublicationDataDermA Real World Analysis of Apremilast and Cardiometabolic Comorbidities in Psoriasis and Psoriatic Arthritis, Including Impact on Weight Loss by Diabetic StatusDownload
PublicationDataDermNatural History of Keloids: A Sociodemographic Analysis Using Structured and Unstructured DataRead more
PublicationDataDermReal-World Dupilumab Continuation in US Adults With Atopic Dermatitis Over a 24-Month PeriodDownload
PublicationAICardioFindings From a Non-Alcoholic Steatohepatitis (NASH) Cohort Developed via Artificial Intelligence in a Large Representative Population in the U.S.Download
PublicationDataCardioCharacteristics of Asymptomatic Heart Failure Patients with Reduced Ejection Fraction in a Large US-Based Real-World CohortDownload
PublicationDataCardioDefining Provider Prescribing Preference as an Instrumental Variable: A Case Study of NOACs in Stroke PreventionDownload
PublicationRegistriesOtherApplication of E-Value Analysis to Gauge Unmeasured Confounding in Real-World Data (RWD) StudiesDownload
PublicationDataOncologyImpact of Population Characteristic on Recall Rates: Initial Finding from a Learning Health SystemDownload
PublicationRegistriesOncologyEffect of Breast Cancer Screening Modality Order on Recall, Cancer Detection Rates, and Positive Predictive Value 1 for Women with Multiple Screening ExamsDownload
PublicationDataGastroMethod To Derive A Crohn’s Disease Activity Index From Electronic Health Records DataDownload
PublicationDataRespiratoryHarmonized Outcome Measures for Use in Asthma Patient Registries and Clinical PracticeDownload
PublicationDataDermReal-World Use of Biologics and Prescription Topical Medications in Pediatric Psoriasis in a Large Dermatology Network in the U.S.Download
PublicationDataDermCharacterization of Patients with Co-morbid Dermatological and Mental Health ConditionsRead more
PublicationDataDermComparison of Improvements in Psoriatic Arthritis Disease Activity between Classes of Biologic Disease Modifying Anti-Rheumatic Drugs in Routine Clinical PracticeDownload
PublicationDataDermPatient-Reported Outcomes and Changes in DMARD Therapy Among Psoriatic Arthritis Patients Treated in Routine Clinical Practice.Download
PublicationDataDermReal-World Characterization and Management of Alopecia Areata Patients in the U.S.Download
PublicationDataDermPatient Characteristics and Social Determinants of Health in a Large Real-World Cohort of Vitiligo Patients in the U.S.Download
PublicationDataDermReal-World Dupilumab Continuation in US Children and Adolescents With Atopic Dermatitis Over a 24-Month PeriodDownload
PublicationDataDermDiabetes and obesity burden and improvements in cardiometabolic parameters in patients with psoriasis or psoriatic arthritis receiving apremilast in a real-world setting.Download
PublicationAICardioIdentifying Progressing Patients in an Artificial Intelligence (AI) Based Cohort of Nonalcoholic Steatohepatitis (NASH)Download
PublicationDataCardioVariation in Outcome Measures in Atrial Fibrillation Registries and the Need for HarmonizationDownload
PublicationDataCardioThe Association Between Social Determinants of Health and 1-Year Survival Among Patients with Heart Failure in a Real-World CohortDownload
PublicationDataNeuroReal-World Switching Patterns Among US Generic Glatiramer Acetate Multiple Sclerosis PatientsDownload
PublicationDataNeuroRevisiting MS Prevalence in the 21st Century: Exploration Based on a Large Representative US-Based Real-World CohortDownload
PublicationAINeuroPredicting Relapse Episodes in Patients with Multiple Sclerosis Treated with Disease Modifying Therapies in a Large Representative US-Based Real World CohortDownload
PublicationDataNeuroTreatment Patterns and Reasons for Switching among U.S. Patients with Multiple Sclerosis Taking the Glatiramer Acetate Class of ProductsDownload
PublicationDataNeuroA Real-World Retrospective Analysis of Outcomes in Multiple Sclerosis Patients Who Transitioned to Alemtuzumab After Rituximab or OcrelizumabDownload
PublicationDataNeuroComparison of Symptoms, Treatments, and Healthcare Resource Utilization in Patients with Multiple Sclerosis by Sex in a Real-World Cohort in the U.S.Download
PublicationDataNeuroAssessing Comorbid Behavioral Health Conditions, Healthcare Resource Utilization, and Medication Use in Patients Seeking Mental Health Care within a Large, Representative Real-World Multiple Sclerosis RegistryDownload
PublicationReal-World Adherence, Discontinuation, and Switching among Patients with Multiple Sclerosis Initiating Generic Glatiramer Acetate from Two Large Real-world Databases in the United StatesDownload
PublicationDataNeuroAssessing the Expanded Disability Status Scale in Secondary Progressive Multiple Sclerosis Patients Treated with Disease Modifying Therapies within a Large, Representative Real World Multiple Sclerosis RegistryDownload
PublicationAINeuroCharacterizing Disease Progression in Multiple Sclerosis Subtypes Using RWD: Feasibility of Applying a Machine Learning Model to Address Missing DataDownload
PublicationNeuroPatient and Provider Characteristics Associated with PHQ-9 Administration and Outcomes Assessment in Routine Clinical PracticeDownload
PublicationDataMental HealthPatient & Provider Characteristics Associated with PHQ-9 Administration and Outcomes Assessment in Routine Clinical Practice: Findings from the OM1 Intelligent Data CloudDownload
PublicationDataMental HealthDepression and Patient Outcomes Among Rheumatoid Arthritis Patients in a Large US-Based Real World CohortDownload
PublicationDataMental HealthEvaluating the Feasibility of Capturing a Core Set of Harmonized Depression Outcome Measures in Primary Care and Mental Health Patient RegistriesDownload
PublicationDataMental HealthWeight Gain and Treatment Interruptions With Second-Generation Oral Antipsychotics: Analysis of Real-World Data Among Patients With Schizophrenia or Bipolar I DisorderDownload
PublicationAIMental HealthUse of a Natural Language Processing-Based Approach to Extract Depression Symptom Severity and Suicide Ideation from Clinical Notes to Support Depression ResearchDownload
PublicationDataMental HealthChanges in Weight Across the Life Span in Patients with Bipolar Disorder I Treated with Second Generation AntipsychoticsDownload
PublicationDataMental HealthThe Association Between Race, Social Determinants of Health, and Treatment for Major Depressive Disorder (MDD) in a Real-World CohortDownload
PublicationAIMental HealthThe Association Between Credit Risk Score and Major Depressive Disorder Burden Using a Machine Learning Estimation of the PHQ-9 in a Real-World CohortDownload
PublicationAIMental HealthDevelopment of a Machine Learning Model for Estimating PHQ-9 Scores Using Clinical Notes from Real-World Data SourcesDownload
PublicationAIMental HealthUse of Medical Language Processing in Real-World Data to Understand Antidepressant Side Effects and Improve Research in Mental HealthDownload
PublicationAIMental HealthIdentification of Treatment Resistant Major Depressive Disorder using a Machine Learning AlgorithmDownload
PublicationDataMental HealthAddressing Gaps in Real-World Data Sources through Automated Extraction of Psychiatric Comorbidities and Medication Side Effects from Clinical NotesDownload
PublicationDataMental Healthhe Association Between Adherence to Esketamine Nasal Spray Therapy Dosing Regimen and Changes in Depressive Symptoms Among Patients With Treatment-Resistant Depression in the U.S.Download
PublicationDataMental HealthSuicidal Ideation in Patients Treated with Glucagon-like Peptide 1 Receptor (GLP1) Agonists: A Retrospective Real-World AnalysisDownload
PublicationAIMental HealthAI-Based Estimation of the CGI-I to Address Gaps in Real-World Data and Increase Study Sample SizeDownload
PublicationDataRheumPatient Reported Outcomes and Changes in DMARD Therapy for Rheumatoid Arthritis in Routine Clinical PracticeDownload
PublicationDataRheumInitiation of Biologic Disease Modifying Antirheumatic Drug Therapy and Associated Changes in Disease Activity Measures in Routine Clinical Practice: Findings from a Next Generation RegistryDownload
PublicationDataRheumComparison of Improvements in Disease Activity between Classes of Biologic Disease Modifying Anti-Rheumatic Drugs in Routine Clinical Practice: Findings from a Large Contemporaneous Real World CohortRead more
PublicationDataRheumInitiation of Biologic Disease Modifying Antirheumatic Drug Therapy and Associated Changes in Disease Activity Measures in Routine Clinical Practice: Findings from a Large Contemporaneous Real World CohortDownload
PublicationDataRheumTreatment Patterns in Large Vessel Arteritis (Giant Cell Arteritis and Temporal Arteritis): Findings from a Large Contemporaneous Real-World Cohort in the U.S.Download
PublicationDataRheumAge and Gender Differences in Comorbidities among Patients with Rheumatoid Arthritis in a Large US-Based Real World CohorDownload
PublicationDataRheumPatient Characteristics and Current Management of Systemic Lupus Erythematosus Patients in a Large, Representative US-Based Real World CohortDownload
PublicationDataRheumImprovements in Disease Activity Scores Associated with bDMARD use by Rheumatoid Arthritis Patients in a Large US-Based Real World CohortDownload
PublicationDataRheumAvailability of Disease Activity Measures from Systemic Lupus Erythematosus Patients in a Large, Representative US-Based Real World Registry CohortDownload
PublicationDataRheumPatient Characteristics and Management Of Juvenile Idiopathic Arthritis (JIA) In a Large, Representative Real-World CohortDownload
PublicationDataRheumCharacteristics and Disease Management in a Large Real-World Lupus Nephritis Cohort in the U.S.Download
PublicationDataRheumPredictors of Improvement in Tender Joint Counts Among Patients with Systemic Lupus Erythematosus in A Large, Representative US-Based Real-World Registry Cohort. Download
PublicationDataRheumJoint Involvement and Disease Activity in Systemic Lupus Erythematosus (SLE) Patients: Calculation of Swollen to Tender Joint Count Ratio in a Real-World Cohort in the U.S.Download
PublicationDataRheumAssessing Comorbid Inflammatory Arthritis Conditions and Swollen to Tender Joint Count Ratios in a Real-World Systemic Lupus Erythematosus CohortDownload
PublicationDataRheumAn Evaluation of Real-World Use of Biologics in Rare Systemic Vasculitides During Routine Clinical Care in the USDownload
PublicationDataRheumCharacterizing Patients Initiating Abaloparatide, Teriparatide, or Denosumab in a Real-World Setting: a US Linked Claims and EMR Database AnalysisDownload
PublicationDataRheumHarmonized Outcome Measures for Use in Degenerative Lumbar Spondylolisthesis Patient Registries and Clinical PracticeRead more
PublicationAIRheumComparison of an AI–Enabled Patient Decision Aid vs Educational Material on Decision Quality, Shared Decision-Making, Patient Experience, and Functional Outcomes in Adults with Knee Osteoarthritis: A Randomized Clinical TrialRead more
PublicationAIDataRheumValidation of a Machine Learning Approach to Estimate Systemic Lupus Erythematosus Disease Activity Index Score Categories and Application in a Real-World DatasetDownload
PublicationAIDataRheumPrediction of Non-Response to First-Line Methotrexate Treatment in Rheumatoid Arthritis: A Real-World Data Analysis Using Machine LearningDownload
PublicationDataRheumPatient Characteristics and Outcomes in Patients with Rheumatoid Arthritis Treated with Upadacitinib: The OM1 RA RegistryDownload
PublicationDataRheumCharacterizing Non-Response to Methotrexate Monotherapy Among Rheumatoid Arthritis Patients in a Large Real-World Longitudinal CohortDownload
PublicationAIRheumValidation of a Machine Learning Approach to Estimate Clinical Disease Activity Index Scores for Rheumatoid ArthritisRead more
PublicationDataRheumA Cross-Sectional Study of Rheumatoid Arthritis (RA) Diagnoses in Patients with Systemic Lupus Erythematosus (SLE)Download
PublicationDataRheumEffect of Patient Reported Outcomes on Changes in DMARD Therapy Among Rheumatoid Arthritis Patients Treated in Routine Clinical PracticeDownload
PublicationDataRheumCharacterization of Non-radiographic Axial Spondyloarthritis Patients and the Burden of Disease in Routine Clinical PracticeDownload
PublicationDataRheumImpact of Change in Biologic Disease Modifying Antirheumatic Drug Therapy on Disease Activity Measures: Findings from a Large Contemporaneous Real-World Longitudinal Database of Rheumatoid Arthritis PatientsDownload
PublicationDataRheumImpact of Change in Biologic Disease Modifying Antirheumatic Drug Therapy on Disease Activity Measures: Findings from a Large Contemporaneous Real-World Longitudinal Database of Psoriatic Arthritis PatientsDownload
PublicationAIRheumMachine Learning Models to Estimate Disease Activity Measures in Real-World Data Sources: Lessons Learned from Four Autoimmune DiseasesDownload
PublicationAIRheumLessons Learned from the Development of Machine Learning Models to Estimate Validated Measures of Disease Activity and Symptom Severity Using Real-World Data for Four Chronic ConditionsDownload
PublicationDataRheumDisease Activity in Rheumatoid Arthritis Patients Initiating Anti-Obesity Medication in a Longitudinal US-Based Real-World CohortDownload
PublicationDataRheumPredictors of Low Disease Activity/ Remission Amongst Rheumatoid Arthritis Patients Experiencing Inadequate Response to Biologic/ Targeted Synthetic Disease-Modifying Antirheumatic DrugsDownload
WhitepaperRegistriesManaging Missing Patient Data in Registries: Addendum to Registries for Evaluating Patient Outcomes, 3rd Edition.Read more
WhitepaperRegistriesBiorepositories: Addendum to Registries for Evaluating Patient Outcomes, 3rd Edition.Read more
PublicationAIOncologyMammographic Screening in Routine Practice: Multisite Study of Digital Breast Tomosynthesis and Digital Mammography ScreeningsDownload
Webinar & VideoAIFrom Promise to Reality: How AI Is Transforming Registries for Post-Approval Evidence GenerationRead more
Webinar & VideoAIRedefining Evidence Generation: Innovative AI-Enabled Approaches for a New Era of TherapiesRead more
Webinar & VideoRegistriesBehind the Insights: Ep 06 FDA Draft Guidance on Post-Approval Data for Cell & Gene TherapiesRead more
Webinar & VideoAIDataRheumFrom Subtyping to Measuring and Predicting Outcomes: How AI is Changing Rheumatology and Immunology ResearchRead more
PublicationDisease Severity at Advanced Therapy Initiation in Real-World Psoriasis Patients in the U.SDownload
BlogUnderstanding Remission: Predictors of Low Disease Activity in Rheumatoid Arthritis Patients Experiencing Inadequate Response to b/tsDMARDSRead more
News & ArticleAIRheumOM1 Rheumatoid Arthritis Dataset Rated High Quality as Cornerstone AI Partnership Speeds Future Quality ReviewsRead more
News & ArticleDataNeuroOM1 expands neurology network to over 3 million patients for real-world data researchRead more
News & ArticleDataNeuroOM1 Adds a Half Million Patients to Neurology Network, Strengthening Real-World Evidence Generation and Accelerating Innovation in NeurologyRead more
Webinar & VideoDataRheumBehind the Insights: Ep 05 Rheumatoid Arthritis Remission with Chandra Gopalakrishnan, MD, MPHRead more
Webinar & VideoAIMental HealthPredicting Response and Personalizing Treatment Decisions in Mental Health: New Opportunities with AI and Real-World DataRead more
Webinar & VideoAICardioMental HealthBehind the Insights: Ep 04 GLP-1s & Suicidal Ideation, Jessica Probst, MPH & Carl Marci, MDRead more
News & ArticleAIMental HealthUnderstanding the link between GLP-1 therapies and suicidal ideation using real-world dataRead more
News & ArticleAIOM1’s PhenOM® Foundation AI Surpasses One Billion Years of Health History in Model TrainingRead more
Webinar & VideoRegistriesRethinking Evidence: Leveraging Real-World Data to Accelerate Drug DevelopmentRead more
News & ArticleDataMental HealthOM1 to Present Groundbreaking Research on GLP-1 Agonists and Suicidal Ideation at ISPOR 2025Read more
News & ArticleDataCardioMental HealthOM1 to Present Groundbreaking Research on GLP-1 Agonists and Suicidal Ideation at ISPOR 2025.Read more
News & ArticleDataMental HealthOM1 expands mental health network to over six million patients, enhancing real-world evidence and personalized care capabilitiesRead more
News & ArticleDataMental HealthOM1 Adds 1 Million Patients to Its Mental Health Network, Significantly Expanding Specialty Coverage and Driving New Possibilities for Real-World Research and Personalized CareRead more
Webinar & VideoAIMental HealthBehind the Insights: Ep 03 Decoding Treatment-Resistant Depression with Carl Marci, MDRead more
Webinar & VideoRegistriesBehind the Insights: Ep 02 The Next Era of Evidence Generation with Rich Gliklich, MDRead more
News & ArticleAIOM1 Expands into Europe to Strengthen Support for Life Sciences with AI-Driven Real-World Evidence SolutionsRead more
Webinar & VideoAIDermBehind the Insights: Ep 01 AI in Dermatology Real-World Data with Joseph Zabinski, PhD, MEMRead more
Webinar & VideoRegistriesGastroTransforming Cancer Detection: The Power of Real-World Evidence and AI in Multi-Cancer Early Detection (MCED) StudiesRead more
News & ArticleDataNeuroNalu PNS System Significantly Reduces Healthcare-Related Costs in Chronic Pain PatientsRead more
News & ArticleAIDermAmerican Academy of Dermatology launches innovative project to improve outcomes for patients with hidradenitis suppurativaRead more
News & ArticleDataMental HealthMDMA Therapy for Mental Health Conditions: Do the Benefits Outweigh the Risks?Read more
News & ArticleAIJoseph Zabinski Of OM1: How AI Is Disrupting Our Industry, and What We Can Do About ItRead more
News & ArticleAIAI and Real-World Evidence: Transforming Pharmaceutical Research and Market AccessRead more
News & ArticleDataAINeuroQ&A: New Alzheimer’s dataset allows ‘whispers from the brain’ to assist in early detectionRead more
News & ArticleAIMental HealthPeople are using ChatGPT as a therapist. Mental health experts have some concernsRead more
News & ArticleAIRegistriesDataOM1 Earns Frost & Sullivan's 2024 North American New Product Innovation Award for Transforming Real-world Evidence Analytics Solutions Industry with Its Pioneering AI-powered PlatformsRead more
Webinar & VideoRegistriesRevolutionizing Prospective Studies and Registries with Automation and AIRead more
Webinar & VideoAIMental HealthUnveiling the Unseen: AI's Role in Identifying Treatment-Resistant DepressionRead more
News & ArticleAINeuroOM1 Contributes to Alzheimer’s Disease Research With New PremiOM Dataset of Over 1 Million PatientsRead more
News & ArticleRegistriesHow can Life Science Technology Providers Support the Pharmaceutical Industry in the Transition Toward More Digitally Connected Operations?Read more
News & ArticleDataPanalgo and OM1 Expand Partnership to Offer OM1's PremiOM Datasets in Panalgo's IHD Analytics PlatformRead more
News & ArticleRegistriesOM1, a Pioneer in Patient Registries, Launches Registries Center of ExcellenceRead more
News & ArticleRegistriesOM1, a Pioneer in Patient Registries, Launches Its Registries Center of ExcellenceRead more
News & ArticleAIAI in Healthcare – Enhancing Treatment Plans, Engaging Patients, and Impacting Patient OutcomesRead more
News & ArticleAIDermOncologyJoseph Zabinski, PhD, MEM: Navigating the Future of AI in Skin Cancer DetectionRead more
Webinar & VideoAIPractical AI: Adding Insight to the Patient Journey with Digital PhenotypingRead more
News & ArticleAIOM1 Launches Three New Products Powered by Patented AI Platform to Expedite Delivery of Personalized MedicineRead more
PodcastAIHow AI-Powered Phenotyping Enhances the Patient Journey for Life Science ApplicationsRead more
News & ArticleAIDermJoseph Zabinski Advocates for Patient Trust in AI Adoption in Dermatology CareRead more
News & ArticleDataOtherOM1 and Medtronic Partner on Propel Study to Assess Long-term Outcomes for Patients With Chronic RhinosinusitisRead more
Webinar & VideoRegistriesIntegrated Evidence Generation: Exploring Registries in the Era of AutomationRead more
News & ArticleAIDermDr Joseph Zabinski Discusses Using Artificial Intelligence to Identify Patients With GPPRead more
News & ArticleAIMental HealthIntegrating Ambient Clinical Voice Technology – The Impacts, Challenges, and BenefitsRead more
News & ArticleRegistriesWhat strategies are being employed to accelerate product development and commercialization without compromising quality?Read more
News & ArticleAINeuroMachine Learning Model Enhances Real-World Studies for Predicting Disability Progression in Multiple SclerosisRead more
News & ArticleAIRareRare Disease Detection With AI: What Tools to Trust (stand alone feature)Read more
News & ArticleAIBalancing Innovation and Digital Transformation with Regulatory Compliance and Patient SafetyRead more
News & ArticleAICardioGastroAI Identifies Clinical Phenotypes of Rapid Fibrosis Progression in MASHRead more
News & ArticleAIA cancer battle, AI, and starting healthcare companies: Our top podcasts of 2023Read more
News & ArticleRegistriesWhat Do You See As The Most Significant Regulatory Decision Or Guidance On The Horizon For 2024 (Or Beyond)?Read more
News & ArticleRegistriesWhat Do You Think Was The Single Most Consequential Event Or Result In Pharma/Biopharma In 2023?Read more
News & ArticleRegistriesA new era of integrated evidence generation: Deep dive into OM1 case study spotlight from the DIA Real-World Evidence Conference 2023Read more
News & ArticleDataWomen in Science: Kathryn Starzyk on the power and complexities of real-world evidenceRead more
News & ArticleAINeuroDr Carl Marci talks real-world data, early detection of Parkinson’s and how personalized intervention is key to quality of life.Read more
News & ArticleDataRespiratoryOM1 Launches Asthma and Chronic Rhinosinusitis Datasets to Expand RWERead more
News & ArticleDataDermStefan Weiss, MD, Discusses OM1’s New HS Dataset and Expanded Dermatology NetworkRead more
News & ArticleDataRespiratoryOM1 Launches Asthma and Chronic Rhinosinusitis Datasets to Expand Real-World Evidence in Respiratory and ENTRead more
News & ArticleDataDermOM1 Launches HS Dataset to Expand Use of Real-World Evidence in DermatologyRead more
News & ArticleDataDermOM1 Launches Hidradenitis Suppurativa Dataset to Expand Real-World Evidence in DermatologyRead more
PodcastAINeuroThe Sooner, the Better: Detecting and Decoding Alzheimer’s with Real-World DataRead more
News & ArticleRegistriesReclaiming registries for integrated evidence generation throughout the product life cycleRead more
News & ArticleRegistriesWhat Piece of Conventional Industry Wisdom Do You Think is Misguided, Outdated, or Just Plain Wrong?Read more
News & ArticleRegistriesHow Is Your Organization Currently Leveraging Real-World Data/Evidence and What Uses Do You Anticipate in the Future?Read more
News & ArticleDataNeuroOM1 Launches Parkinson’s Disease Premium Dataset to Expand Real-World Evidence in NeuroscienceRead more
News & ArticleDataMental HealthEXPERT PRAISES PROPOSED FEDERAL RULE TO STRENGTHEN BEHAVIORAL HEALTH PARITYRead more
News & ArticleQ1. In what areas of pharma/biopharma are you most excited to see increased adoption of artificial intelligence (AI) and machine learning?Read more
News & ArticleRegistriesOM1 to Expedite and Improve Research With New Study Automation Platform & Evidence Generation SolutionRead more
News & ArticleRegistriesWalgreens, Freenome Team Up, New AI Products from ObjectiveHealth, Saama, MoreRead more
News & ArticleAIDermAmerican Academy of Dermatology launches innovative project to improve outcomes for patients with life-threatening pustular psoriasisRead more
News & ArticleAIMental HealthMachine learning model accurately estimates PHQ-9 scores from clinical notesRead more
Case StudyRegistriesOncologyEmpowering unprecedented real-world analyses of breast cancer screening outcomesRead more
News & ArticleDataDermUnderstanding How Data Analytics Help Improve Health Outcomes With Stefan Weiss, MDRead more
News & ArticleAIMental Health“I Know It When I See It”: Definitions of Treatment-Resistant DepressionRead more
News & ArticleDataMental HealthHow Real-World Data Can Contribute to Improved Mental Health TreatmentRead more
News & ArticleDataMental HealthOM1 Launches Analytics to Deliver Mental Health & Immunology Insights on Prescriber Trends and Therapy EffectivenessRead more
News & ArticleAIRheumPeek Behind the Poster: Machine learning to estimate disease activity measures for autoimmune diseases in real-world data sourcesRead more
News & ArticleRegistriesOncologyNew mammography guidance throws another twist into screening debateRead more
News & ArticleDataAIRheumAmplifying lupus disease activity with real-world data and machine learningRead more
News & ArticleAIUsing Artificial Intelligence to Get the Right Drug to the Right Patient at the Right TimeRead more
Case StudyRegistriesOncologyLarge-Scale Comparative Study for Cancer Screening for Label ExpansionRead more
News & ArticleAIMental HealthAs suicide rates spike, new AI platform could ‘fill the gap’ in mental health care, say Boston researchersRead more
News & ArticleAIOM1 Unveils Patented, AI-powered Platform to Accelerate Personalized MedicineRead more
News & ArticleAIDataDermDermatology Data Can Direct Policy Priorities, but Gaps Reflect Inequities of CareRead more
News & ArticleDataAIRheumRAPID3 Scores May Help Determine the Impact of DMARD Therapy on PsA SeverityRead more
News & ArticleDataClinical investigators need to be wary of confounding and bias in real-world studies; here is what to look for and how to address itRead more
News & ArticleAIOncologyBiden's 'Cancer Moonshot' is already being fueled by tech addressing breast cancerRead more
News & ArticleAIMental HealthHard to Define, Harder to Find Patients: Using AI & Real-World Data to Understand Treatment Resistant DepressionRead more
News & ArticleDataMental HealthOM1 Expands Mental Health Offering With Real-World Datasets Including Schizophrenia and Bipolar DisorderRead more
News & ArticleDataOM1 Launches Analytic Reports Uncovering Causes of Medication Discontinuation in Immunology PatientsRead more
News & ArticleAIWhat do you view as the most disruptive or transformational technology or development on the horizon?Read more
News & ArticleDataRheumKazuki Yoshida, MD, MPH, ScD: Methotrexate Access in the Post-Roe v Wade EraRead more
News & ArticleDataHow’d They Do It? Tech Leaders Reflect on How They Innovated To Solve Health ProblemsRead more
News & ArticleAINeuroUsing Real-World Data for Patients with Multiple Sclerosis: A New Machine Learning Model for the Expanded Disability Status Scale (EDSS)Read more
News & ArticleAIAI Applications for Clinical Development: From Identifying Patients to Amplifying Trial EndpointsRead more
News & ArticleAIOM1 LAUNCHES A NEW ESTIMATION MODEL FOR THE EXPANDED DISABILITY STATUS SCORE (EDSS) FOR MULTIPLE SCLEROSIS PATIENTSRead more
News & ArticleAINeuroValidation of a machine learning approach to estimate expanded disability status scale scores for multiple sclerosisRead more
News & ArticleDataMental HealthReal-World Data Delivers Dose of Hope for Mental Health in the U.S.Read more
PodcastAI#Healthin2Point00, Episode 223 | Carbon Health, Woebot, Eight Sleep, Aidoc, and OM1Read more
News & ArticleAIRWD Powerhouse OM1 Announces $85 Million in Financing to Personalize Healthcare and Target Chronic DiseasesRead more
News & ArticleAIReal-World Data & Technology Company OM1 Closes $85 Million Financing To Make Healthcare More Measured, Precise, And Pre-EmptiveRead more
News & ArticleDataNeuroOM1 Launches Multiple Sclerosis Registry with More than 20,000 Patients Prospectively Followed with Deep Clinical DataRead more
News & ArticleDataRheumOM1 Rheumatoid Arthritis Registry Reaches More Than 200,000 Patients Prospectively Followed With Deep Clinical DataRead more
News & ArticleAIDataDermAmerican Academy Of Dermatology Collaborates With OM1 To Empower More Measured & Precise Care And Treatments For DermatologyRead more
News & ArticleAIOtherDell Medical School helps develop artificial intelligence tool for knee surgeryRead more
News & ArticleAIOtherOM1 Artifical Intelligence (AI) Shared Decision Aid Demonstrates Significant Improvement In Decision Quality And Surgical Outcomes For Knee OsteoarthritisRead more
News & ArticleDataCardioOM1 Heart Failure Registry Reaches More than 140,000 Patients Prospectively Followed with Deep Clinical DataRead more
News & ArticleDataRheumOM1 Giant Cell Arteritis Registry Reaches More Than 5,000 Patients Prospectively Followed With Deep Clinical DataRead more
News & ArticleRegistriesOncologyUsing real-world evidence to support a changing paradigm for cancer screening: A commentaryRead more
News & ArticleDataRheumOM1 Rheumatoid Arthritis Registry Reaches More Than 100,000 Patients Prospectively Followed with Deep Clinical DataRead more
News & ArticleRegistriesDataCardioNew Harmonized Outcome Measures for Atrial Fibrillation Published in HeartRhythmRead more
PublicationRegistriesOtherAddendum to Registries for Evaluating Patient Outcomes: A User’s Guide, 3rd EditionRead more


















































































![WEST PALM BEACH, Fla. — Application of a machine learning model to databases of patients with multiple sclerosis expanded understanding of disease progression, according to a poster at ACTRIMS 2024.“The [Expanded Disability Status Score] is a critical endpoint in clinical trials, but in the real world it’s not routinely collected,” Carl D. Marci, MD, managing director of](/_next/image/?url=https%3A%2F%2Fimages.ctfassets.net%2Fddhe5ahaolzf%2F4REDjTfHWo8BdGhY9fL7m0%2F5ea3f642f251fdeb7a094009955985dc%2Fmachine-learning-ai213593664.jpg&w=3840&q=75)


























![PM360 asked for companies to send in their latest and best ways to improve adherence. Here are twelve of the best examples of programs, strategies, solutions, technology, and more that companies have developed or are using to keep patients on their prescribed therapies. [tab: BrightInsight] PSP+ Companion App BrightInsight Jamie…](/_next/image/?url=https%3A%2F%2Fimages.ctfassets.net%2Fddhe5ahaolzf%2F6LdVlJlgTWUIWLOiY9S9of%2F42ca205e7a66f7b202124fcefe81b471%2FFocus-On-New-Adherence-Solutions-0723.jpg&w=3840&q=75)
![MIAMI BEACH, Fla. — A novel machine learning model accurately estimated scores from a depression questionnaire from complete and partial clinical notes, per a poster at the American Society of Clinical Psychopharmacology annual meeting.“In the real world, there’s a lot of missing data and [Patient Health Questionnaire-9] scores are commonly used and patients record them, but not](/_next/image/?url=https%3A%2F%2Fimages.ctfassets.net%2Fddhe5ahaolzf%2F2wrdaT8JqEIhQnO9DOVyde%2Fc04bff599118eda62ea91d22920aeb7e%2Fdoctor-at-computer_2020.jpg&w=3840&q=75)